Deleting Entries From Open-Address Hash tables


It's no secret that when it comes to search structures, hash tables are fast. Performance wise, a hashtable can be much faster than any of the ordered search tree's frequently discussed in my posts. If your data doesn't require any type of ordereing then they are certainly the associative container of choice. Hashtables also tend to be a bit easier to implement as well. One thing that they do have in common with search tree structures is that you will be hard pressed to find a book that includes an algorithm for removing items from an open addressed hash table.
Hash tables which use separate chaining for their collision resolution get off easy: it's a simple erasure from a linked list. Open address tables on the other hand, are a bit more complicated. That being said, they're not complicated enough to justify something like "Lazy Deletion" where we leave "tombstones" in the table instead of removing them.
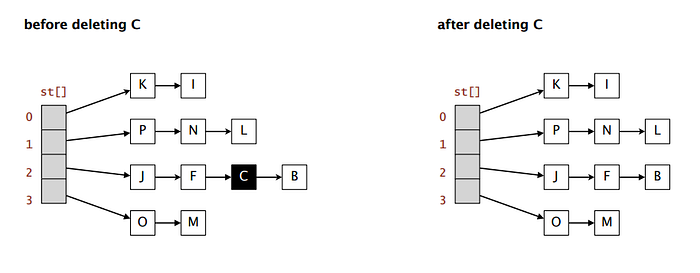
In todays post i'm going to cover a simple algorithm for erasing entries in an open-address hash table.
Table Entries
We can of course, simply store an array of the raw objects, however using an explicit entry structure greatly reduces the complexity of certain operations - like eraseing an entry! They also make searching the table a cleaner operation. This is because by providing a clean interface for testing for occupancy we can avoid having to use null values or some other type of sentinel value which isn't as clear in it's intention, and so harder to read. Code is written for humans to read, in a way that computers can execute. Though i digress...
template <class T>
struct Item {
T info;
bool inuse;
Item(T i) : info(i), inuse(true) { }
Item() : inuse(false) { }
void clear() {
info = T();
inuse = false;
}
};The table will use an array of Item<T> object's to store data.
template <class T>
class HashTable {
private:
Item<T>* table;
int n;
int maxn;
void grow();
public:
HashTable(int sz = 5);
void insert(T info)
void erase(T info);
};Search for the entry
As we do with any other search data structure, the first step in removing an entry is to find the position it is stored at. In a Linear probing table this is done by calculating the index from the hash function, and incrementing by one until we find the item, or an empty slot signifying it isnt in the table.
void erase(T info) {
if (!contains(info))
return;
unsigned int idx = Hash<T>()(info) % maxn;
while (table[idx].inuse && table[idx].info != info) idx = (idx + 1) % maxn;
/* continues below */
Remove the entry
Once the entry has been found, we clear it's slot to remove the desired item from the table. Easy enough, but we're not done quite yet though: if we were to stop now then any other items which hashed to this "bucket" will be lost. Why is this the case? Well I'm going to let you in on a little secret...
/* continued from above */
table[idx].clear();
n--
/* continues below */The "buckets" of an open address hash tables are implicit linked lists! Yep, you read that correctly. We're just computing the index from the hashcode as a substitute for the "next" pointer. With that in mind, what happens to any nodes in a linked list if we remove the node pointing to them without assigning them somewhere else? They still exist, but theres no way to find them.
A Linked List by any other name...
In order for us to remove an entry without losing any remaining data in the slot, we have to shift the remaining entries forward. We do this by continuing from the removed slot to traverse the rest of the entries in the bucket, deleting each as we go, only to immediately re-insert it. This might sound terribly inefficient, but if we have a good hash function and our table does not suffer from a high load factor, than we should never have more than a handful of entries to process in this way.
/* continued from above */
idx = (idx+1) % maxn;
while (table[idx].inuse) {
T toreplace = table[idx].info;
table[idx].clear();
n--;
insert(toreplace);
idx = (idx+1) % maxn;
}
n--;
}And that's all there is to it! I told you it was simple didn't I? Despite the fact I used linear probing in the example, this method will work with any open-address scheme in which the keys strictly increase. This means it will work with quadratic probing, double hashing, etc.
Well, that's what I got for today, until next time Happy Hacking!
Full Implementation
#ifndef hashtable_hpp
#define hashtable_hpp
#include "hash.hpp"
#include "kvpair.hpp"
template <class T>
struct Item {
T info;
bool inuse;
Item(T i) : info(i), inuse(true) { }
Item() : inuse(false) { }
void clear() {
info = T();
inuse = false;
}
};
template <class T>
class HTIterator {
private:
Item<T>* curr;
int offset;
int maxn;
public:
HTIterator(Item<T>* ptr, int max) : curr(ptr), offset(0), maxn(max) {
while (offset < maxn && !curr[offset].inuse) { offset++; }
}
T& get() {
return curr[offset].info;
}
void next() {
do {
offset++;
} while (offset < maxn && !curr[offset].inuse);
}
bool done() {
return offset == maxn;
}
};
template <class T>
class HashTable {
private:
Item<T>* table;
int n;
int maxn;
void resize() {
HashTable<T> tmp(2*maxn);
for (int i = 0; i < maxn; i++)
if (table[i].inuse)
tmp.insert(table[i].info);
table = tmp.table;
maxn *= 2;
}
public:
HashTable(int sz = 5) {
n = 0;
maxn = sz;
table = new Item<T>[maxn];
}
HashTable(const HashTable& ht) {
n = 0;
maxn = ht.maxn;
table = new Item<T>[maxn];
for (auto it = ht.iterator(); !it.done(); it.next()) {
insert(it.get());
}
}
~HashTable() {
}
int size() const {
return n;
}
bool empty() const {
return n == 0;
}
void insert(T info) {
unsigned int idx = Hash<T>()(info) % maxn;
while (table[idx].inuse && table[idx].info != info) idx = (idx + 1) % maxn;
table[idx] = info;
n++;
if (n >= maxn/2) { resize(); }
}
T& search(T info) {
unsigned int idx = Hash<T>()(info) % maxn;
while (table[idx].inuse && table[idx].info != info) idx = (idx + 1) % maxn;
return table[idx].info;
}
bool contains(T info) {
return search(info) == info;
}
void erase(T info) {
if (!contains(info))
return;
unsigned int idx = Hash<T>()(info) % maxn;
while (table[idx].inuse && table[idx].info != info) idx = (idx + 1) % maxn;
table[idx].clear();
idx = (idx+1) % maxn;
while (table[idx].inuse) {
T toreplace = table[idx].info;
table[idx].clear();
n--;
insert(toreplace);
idx = (idx+1) % maxn;
}
n--;
}
HTIterator<T> iterator() {
return HTIterator<T>(table, maxn);
}
HashTable& operator=(const HashTable& ht) {
if (this != &ht) {
n = 0;
maxn = ht.maxn;
table = new Item<T>[maxn];
for (auto it = ht.iterator(); !it.done(); it.next()) {
insert(it.get());
}
}
return ht;
}
};
#endif-
Streaming Images from ESP32-CAM for viewing on a CYD-esp32
-
Constructing the Firsts Set of a Context Free Grammar
-
Inchworm Evaluation, Or Evaluating Prefix-Expressions with a Queue
-
Data Structures For Representing Context Free Grammar
-
A B Tree of Binary Search Trees
-
Implementing enhanced for loops in Bytecode
-
Top-Down Deletion for Red/Black Trees
-
Function Closures For Bytecode VMs: Heap Allocated Activation Records & Access Links
-
Pascal & Bernoulli & Floyd: Triangles
-
A Quick tour of MGCLex
Leave A Comment
Other Readers Have Said:
By: On:
Здравейте, исках да знам цената ви.